
1. Introduction: The New Era of Compute Power
We are entering a new industrial revolution driven by intelligence rather than machinery. The world’s hunger for computational power, specifically the kind required to train and run machine learning (ML) models, is surging. As AI models grow exponentially in size and complexity, they demand massive computational resources, turning compute capacity into the fuel of progress.
The rapid evolution of deep neural networks has led to an exponential increase in computational complexity. For instance, OpenAI’s GPT-3 required 1,000 NVIDIA Tesla V100 GPUs, equivalent to 355 years of training on a single device. These escalating computer needs create barriers for smaller developers who lack the resources to keep up. As computing power becomes a bottleneck for innovation, the need for decentralized solutions like Gensyn becomes clearer.
2. Why Is AI Compute So Expensive?
2.1. The Complexity of Transformer Models
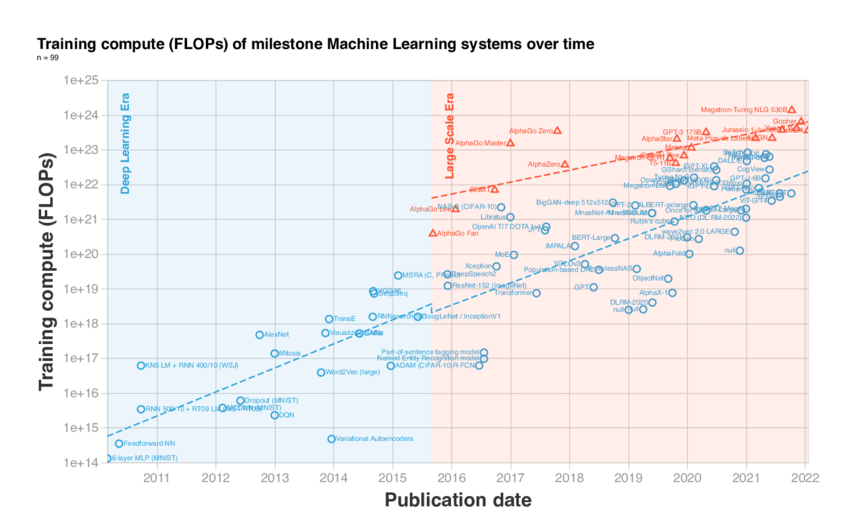
Now, every time the AI tries to answer a question or make a prediction, it has to go through these billions of pieces and do a lot of math (called FLOPs—short for floating point operations). The AI does this math forward and backward while it’s learning, like trying to fit pieces into place and then checking if they fit. Each time it checks, the math gets way more complicated. So, when the AI is training (learning how to get better at its tasks), it ends up doing an enormous amount of math—so much that it’s one of the most computationally expensive things humans have ever done. It’s like solving a huge puzzle over and over again, requiring tons of brainpower (or in this case, computer power). That’s why training these big AI models takes a massive amount of time and computing resources.
The explosive growth in the complexity of models drives the computational expense of AI. Today’s leading models, like GPT-3 and Meta’s LLaMA, rely on transformer architectures, which have billions of parameters.
In tech language, GPT-3 contains 175 billion parameters, and every forward pass during inference requires 2np FLOPs, where n is the token sequence length and p is the number of parameters.
By simpler terms, every time the AI tries to solve a problem (like answering a question or generating text), it has to look at each of these billions of pieces and figure out how they fit together. The more pieces there are, the harder and more time-consuming it becomes to process information, which makes the entire process computationally expensive. GPT-3, for example, has 175 billion of these “puzzle pieces,” and each time it processes data, it’s like trying to match all of them together.
In short, as the AI models grow bigger, solving the “puzzle” becomes more expensive in terms of computing power and resources.
2.2. The Memory Bottleneck and Specialized Hardware

The massive size of these models also drives their memory requirements through the roof. With GPT-3’s 175 billion parameters requiring 700GB of memory, no single GPU can handle the full weight of the model, forcing developers to split models across multiple GPUs using advanced techniques like partitioning and weight streaming.
Note:
- Partitioning: Since one GPU can’t handle the entire model, developers split the model into smaller parts.
- Weight Streaming: Even after splitting the model, sometimes each part is still too big for a GPU to manage all at once. In that case, developers use a method called weight streaming, which means they only load the necessary pieces (or parameters) into the GPU when they are needed, rather than keeping everything in memory all the time.
This is why specialized hardware like Nvidia A100 GPUs have become indispensable for AI tasks. While the A100 boasts 312 teraflops (TFLOPS) of nominal performance, getting the data to the GPU’s tensor cores without bottlenecks in memory transfer is a significant challenge. Optimizing these architectures for data throughput and parallel processing is a must to manage both memory and computational loads.
3. Gensyn’s Solution: The Future of Decentralized Compute
3.1. The Decentralization Compute from Gensyn helps reduce cost
Gensyn’s decentralized computing model is designed to counteract the cost and access issues posed by centralized cloud providers. Gensyn allows developers to access latent compute resources, such as GPUs in data centers or even consumer devices via a blockchain-powered platform. By decentralizing compute power, Gensyn provides on-demand access to a global pool of resources that would otherwise be underutilized.
The Gensyn Protocol utilizes cryptographic verification to ensure trustless interactions between participants. Solvers, verifiers, and submitters interact on the network to complete AI tasks, and the system uses a Truebit-style incentive game to verify results without needing replication of work. This reduces overhead costs and makes the system far more efficient than traditional methods.
By distributing tasks dynamically, Gensyn provides low-latency access to a global pool of GPUs. Whether it’s high-end Nvidia A100s or consumer-grade GPUs, Gensyn’s platform allows developers to match their workloads to the appropriate level of computational power. This opens the door to cost savings while ensuring that even smaller developers can participate in cutting-edge AI research.
3.2. Scalability and Efficiency
The core of Gensyn’s solution is its probabilistic proof-of-learning system, which allows it to verify completed ML tasks without requiring full replication of work. This verification is achieved by using metadata from the training process, creating proofs of learning that can be quickly validated through graph-based pinpoint protocols. While centralized cloud systems face limitations in data throughput and memory, Gensyn’s decentralized model spreads workloads across a network of nodes, avoiding the bottlenecks seen in traditional systems. This allows for greater flexibility, enabling Gensyn to scale with the growing demand for computing resources. This system makes Gensyn far more efficient than blockchain protocols like Ethereum, which are ill-suited for deep learning due to their high replication costs.
With this technology, Gensyn drastically lowers the barriers to entry for accessing high-performance AI infrastructure. The platform’s market-driven pricing structure also ensures that developers pay a fair rate for the compute they use, sidestepping the inflated costs associated with traditional cloud providers.
By distributing workloads across a global network of nodes, Gensyn achieves the scalability necessary to meet the growing demand for AI compute, all while offering low-latency access to GPU resources. Developers can access anything from high-end Nvidia A100s to consumer-grade GPUs, depending on their needs. This allows smaller players to tap into compute resources that were previously out of reach, leveling the playing field.
4. The Economics of Gensyn: Breaking the Cost Barrier
4.1. Reducing the Cost of AI Compute
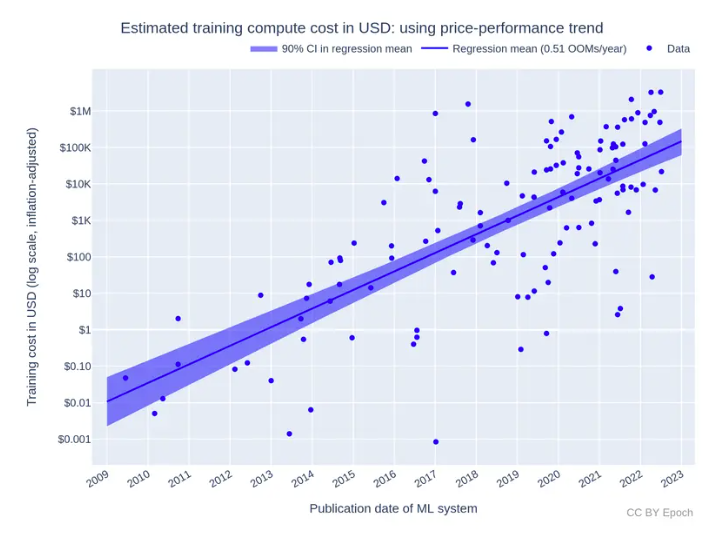
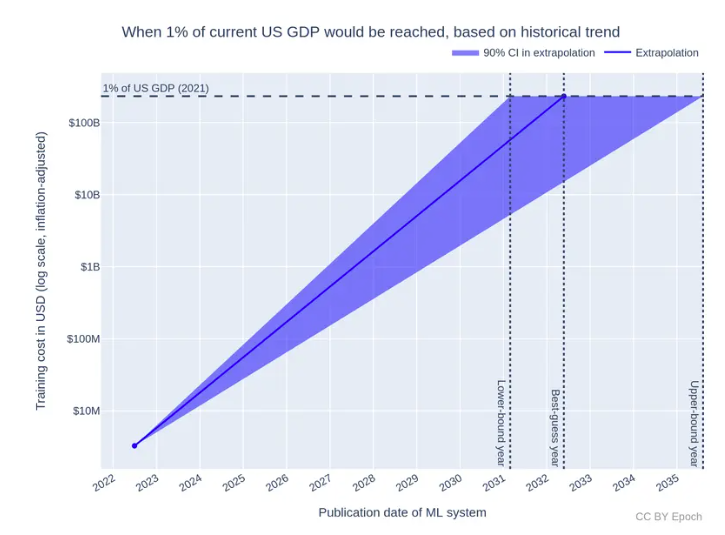
Compute is the accelerant behind the new industrial revolution—an era powered not by steam or electricity, but by intelligence. As AI models become more sophisticated, training costs alone are projected to reach 1% of US GDP in the next 8 years. The demand for computing power has grown exponentially, as demonstrated by Meta’s 2023 LLaMA model, which required $30 million in GPU hardware for training. This demand has been mirrored in the meteoric rise of Nvidia, whose market capitalization eclipsed $1 trillion in 2023, highlighting the immense value of computational hardware in this new landscape.
Training a model like GPT-3 on centralized platforms can cost anywhere from $500,000 to $4.6 million, depending on the efficiency of the hardware and cloud resources used. These costs are driven by the high margins imposed by centralized cloud providers like AWS, Google Cloud, and Azure.
Gensyn dramatically reduces these costs by leveraging underutilized hardware at a fraction of the price. By offering an open marketplace for computing, Gensyn’s decentralized model allows the price of computational power to settle at market-driven rates. This translates into up to 85% cost savings, making AI computing more accessible to a broader range of developers and organizations.
4.2. Dynamic Resource Allocation
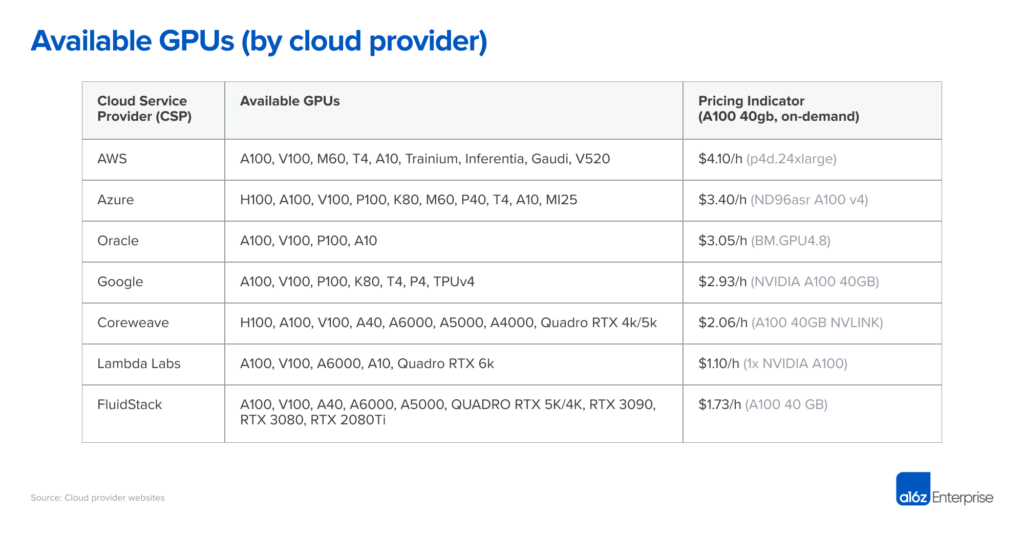
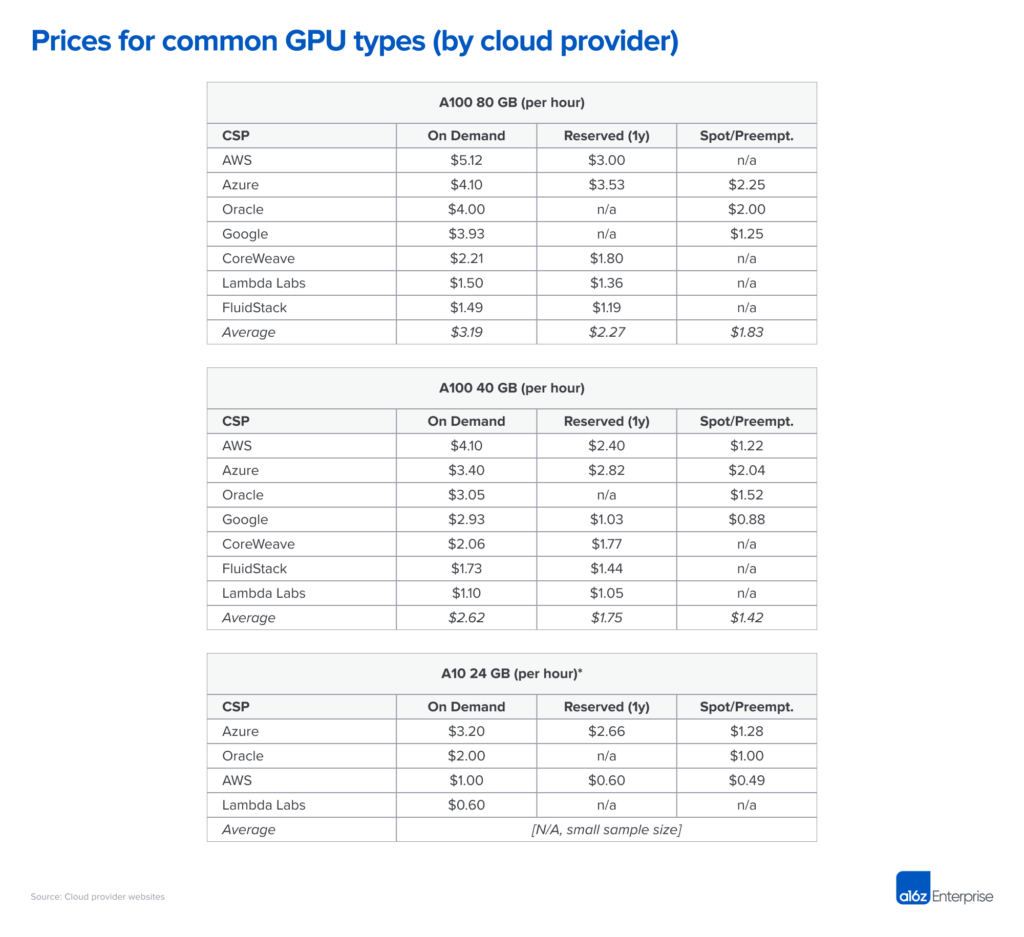
Cloud giants like AWS, Google Cloud, and Microsoft Azure have locked down control over high-performance computing (HPC) infrastructure, making it incredibly expensive to access the computing needed to train AI models. Today, AWS’s p4d.24xlarge instance—one of the most powerful GPU setups—costs over $4.10 per hour per GPU, while their operating margins soar to over 61%. This oligopoly over the computing market has led to price gouging, putting smaller companies at a distinct disadvantage. Gensyn’s decentralized compute marketplace, however, disrupts this monopoly by enabling access to underutilized compute resources from across the globe, democratizing access to the hardware that powers modern AI.
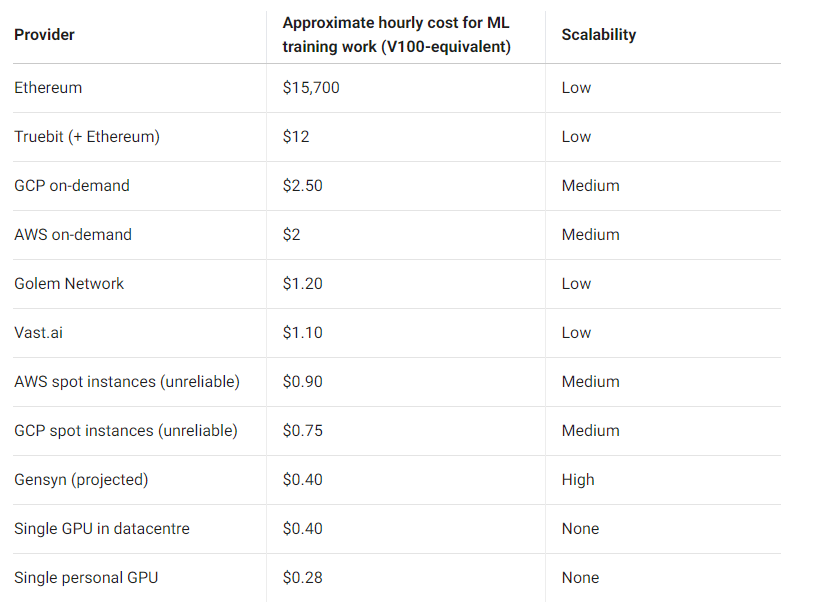
By leveraging underutilized compute resources globally, Gensyn’s protocol can reduce costs by up to 80%. With projected pricing of around $0.40 per hour for an NVIDIA V100-equivalent GPU, Gensyn offers a dramatic reduction from AWS’s $2 per hour cost. This open marketplace for computing power bypasses oligopolistic suppliers and allows prices to be set by market dynamics. Moreover, the move from Ethereum’s proof-of-work to proof-of-stake leaves many miners with powerful GPUs that could now find new life in Gensyn’s network, increasing supply and further reducing costs.
Gensyn’s platform also allows for dynamic resource allocation. Rather than being locked into high-cost, high-performance GPUs, developers can select the type of hardware best suited to their specific needs. For instance, certain inference tasks may not require cutting-edge hardware and can be run on more affordable, consumer-grade GPUs.
This flexibility helps reduce the overall cost of both training and inference. By leveraging shorter floating-point representations (FP16, FP8) and optimizations like sparse matrices, Gensyn can further reduce memory usage and computation time, improving both the efficiency and affordability of AI workloads.
5. Conclusion and Outlook
5.1. Gensyn’s Role in the AI Compute Revolution
The world is undergoing an industrial revolution powered by intelligence, where AI computing resources have become a critical fuel. As AI models rapidly advance and permeate industries from healthcare to finance, the demand for computing infrastructure continues to rise, projected to reach 1% of the U.S. GDP by 2031. This surge in demand creates a pressing need for affordable, scalable, and accessible computing power, a need that Gensyn is uniquely positioned to meet.
Gensyn’s decentralized model provides a breakthrough by unlocking global, underutilized GPU capacity, transforming idle resources into valuable computational power for developers and organizations. This approach democratizes access to AI infrastructure, breaking the stranglehold of centralized cloud giants and opening the door for individuals and smaller players to participate in the AI revolution. By leveraging blockchain technology for secure verification and creating a dynamic, open marketplace, Gensyn is reshaping how AI compute power is accessed and distributed.
5.2. Outlook: A Decentralized Future for AI Compute
Looking forward, Gensyn is poised to play a pivotal role in the future of AI infrastructure. As the traditional centralized model struggles to keep pace with growing AI demands, decentralized solutions like Gensyn offer a scalable, cost-efficient alternative that taps into global resources. This paradigm shift in AI infrastructure will not only lower barriers for smaller developers but also fuel innovation across industries by providing the necessary computational tools to drive AI advancements.
For investors, Gensyn represents a transformational investment opportunity. As AI adoption accelerates, the market for decentralized compute solutions is set to grow exponentially, making Gensyn a key player in the next wave of AI innovation. Its ability to disrupt the centralized cloud infrastructure market while providing an accessible and scalable platform for AI training and inference positions it as a compelling investment for the coming decade.
The information provided in this article is for reference only and should not be taken as investment advice. All investment decisions should be based on thorough research and personal evaluation.


